CoRでRPG作ろうとしたら色々ぶつかった #3
投稿者: 光楼(114)
投稿日:2020/09/19 22:21
光楼(114)
投稿日:2020/09/19 22:21
ギブアップ!!!
前回はメッセージウィンドウを作りました。
実際表示してみると、全て同時に表示されます。
RPGとかでよくある、文字が左から順に表示されていくっていうアニメーション?はありません。
だから今回はそれを作ろうと思ったんですよ。ええ簡単ですよこんなの。文字列を一文字ずつ分解して、それを繰り返し文で順に表示すればいいだけですから。
勿論すぐに出来ましたよ。半角英数は。
半 角 英 数 は 。
一体何があったんだって?
まぁとにかく聞いてくれや。
文字の分解にはsplitが使えます。
これを使って表示部に以下のコードを書いた。
さっそく「うおおお!」が正常に表示されるか試してみよう。
その結果がこれだ↓

ま っ て
違うんだ、私は["う", "お", "お", "お", "!"]と分解されるのを期待してたんだ。
勿論これを全て繋ぐと「うおおお!」になる。
但し一文字ずつ表示させるとなると、なんかバグった感じになる。
このままじゃダメだ……!
なんとかこの問題を解消すべく、文字列分解用の関数を用意した。
さて、どう書いていこうか。
ここでさっきの画像をよく見て欲しい。
「"\201"」←これがよく出てくる。
これが問題解決へのカギに違いない!
きっと文字の区切りか何かだ。この「"\201"」までを1文字と判断するようプログラムを組んだ。
正常に分割できる半角英数対策が大変だ……
さてこれを実行してみる。
まずは「うおおお!」……
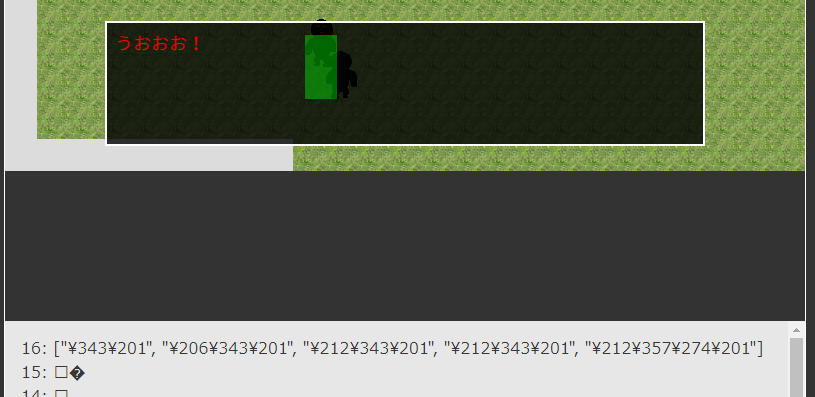
出来た!!!
いやログの表示おかしいけど、上手くいったんですよ(笑)
じゃあ次は「驚かせてすまない。」でいってみよー!
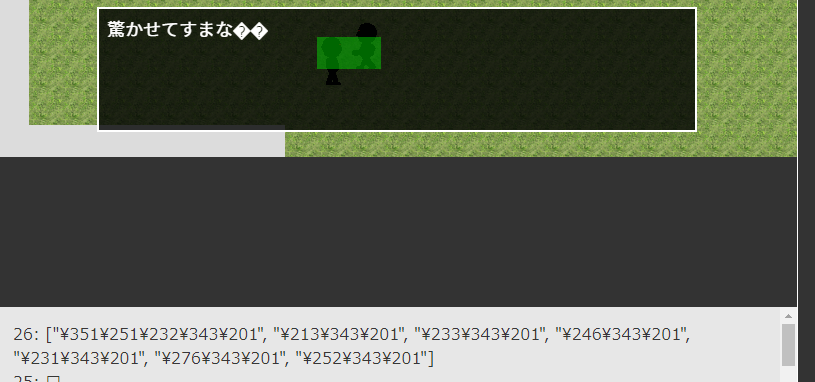
ふぇえええええええええええええ!!!
「い。」の表示に失敗している。
さてここで、「驚かせてすまない。」を分解したときの配列の中身を見てみよう。
そう、後ろの方に「"\201"」が無いのである。
ここで別の方法を考えることにした。
恐らくこれは文字列が1バイト毎に分割されているからこのようになっているのだろう。
ならばこの配列の長さを文字数で割れば、1文字分の長さが分かる!って思ったけど、文字数を得るsizeもバイト数を得るbytesizeも同じ値を示しやがった!
しかも上の配列よく見たら「"\201"」が出てくる間隔が一定じゃない!
チクショウメエエエエエエエエエエエエ!!!
……はい。もうどうしていいのか分からないのでこの件はいったん保留です。
これが出来なくてもRPGは作れるし。
ということで、問題解決のためのアイデアを募集中です!
なにかあればコメントで教えてください!それでは!
ツイート
前回はメッセージウィンドウを作りました。
実際表示してみると、全て同時に表示されます。
RPGとかでよくある、文字が左から順に表示されていくっていうアニメーション?はありません。
だから今回はそれを作ろうと思ったんですよ。ええ簡単ですよこんなの。文字列を一文字ずつ分解して、それを繰り返し文で順に表示すればいいだけですから。
勿論すぐに出来ましたよ。半角英数は。
半 角 英 数 は 。
一体何があったんだって?
まぁとにかく聞いてくれや。
文字の分解にはsplitが使えます。
これを使って表示部に以下のコードを書いた。
#テキストのアニメーション表示
str_arr = m.split('')
debug_log str_arr
print_text = ''
str_arr.each do |item|
print_text += item
debug_log item
message_sprite.text print_text
wait_time(10)
end
さっそく「うおおお!」が正常に表示されるか試してみよう。
その結果がこれだ↓
ま っ て
違うんだ、私は["う", "お", "お", "お", "!"]と分解されるのを期待してたんだ。
勿論これを全て繋ぐと「うおおお!」になる。
但し一文字ずつ表示させるとなると、なんかバグった感じになる。
このままじゃダメだ……!
なんとかこの問題を解消すべく、文字列分解用の関数を用意した。
さて、どう書いていこうか。
ここでさっきの画像をよく見て欲しい。
「"\201"」←これがよく出てくる。
これが問題解決へのカギに違いない!
きっと文字の区切りか何かだ。この「"\201"」までを1文字と判断するようプログラムを組んだ。
#========== 文字列 ==========#
#文字列分割用
def StrSplit(t)
debug_log t
t = t.split('')
debug_log t
set_t = ""
new_t = []
t.each do |item|
set_t << item
f = ('a'..'z') === item || ('A'..'Z') === item || ('0'..'9') === item || ('!'..'~') === item
if item == "\201" || f
debug_log set_t
new_t << set_t
set_t = ""
end
end
return new_t
end
正常に分割できる半角英数対策が大変だ……
さてこれを実行してみる。
まずは「うおおお!」……
出来た!!!
いやログの表示おかしいけど、上手くいったんですよ(笑)
じゃあ次は「驚かせてすまない。」でいってみよー!
ふぇえええええええええええええ!!!
「い。」の表示に失敗している。
さてここで、「驚かせてすまない。」を分解したときの配列の中身を見てみよう。
["\351", "\251", "\232", "\343", "\201", "\213", "\343", "\201", "\233", "\343", "\201", "\246", "\343", "\201", "\231", "\343", "\201", "\276", "\343", "\201", "\252", "\343", "\201", "\204", "\343", "\200", "\202"]
そう、後ろの方に「"\201"」が無いのである。
ここで別の方法を考えることにした。
恐らくこれは文字列が1バイト毎に分割されているからこのようになっているのだろう。
ならばこの配列の長さを文字数で割れば、1文字分の長さが分かる!って思ったけど、文字数を得るsizeもバイト数を得るbytesizeも同じ値を示しやがった!
しかも上の配列よく見たら「"\201"」が出てくる間隔が一定じゃない!
チクショウメエエエエエエエエエエエエ!!!
……はい。もうどうしていいのか分からないのでこの件はいったん保留です。
これが出来なくてもRPGは作れるし。
ということで、問題解決のためのアイデアを募集中です!
なにかあればコメントで教えてください!それでは!
コメントする
コメントするには、ログインする必要があります。
コメント一覧
 qhqh123(投稿日:2020/09/22 20:04,
履歴)
qhqh123(投稿日:2020/09/22 20:04,
履歴)
(そっと応援する音)
光楼(114)(投稿日:2020/09/29 22:42,
履歴)
(そっと感謝する音)
m.split(//)
でどうでしょうか
でどうでしょうか
いっそ、半角英数以外を
全て3バイトとして判定してしまう案
全て3バイトとして判定してしまう案
def StrSplit(t)
#debug_log t
t = t.split('')
#debug_log t
#set_t = ""
new_t = []
counter = 0
t.each_with_index do |item, i|
if counter > 0
counter = counter - 1
else
#set_t << item
if !(('a'..'z') === item || ('A'..'Z') === item || ('0'..'9') === item || ('!'..'~') === item)
#debug_log set_t
new_t << t[i] + t[(i + 1)] + t[(i + 2)]
counter = 2
else
new_t << item
end
end
end
return new_t
end